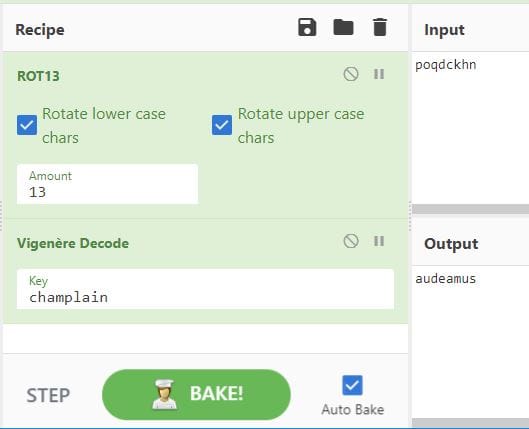
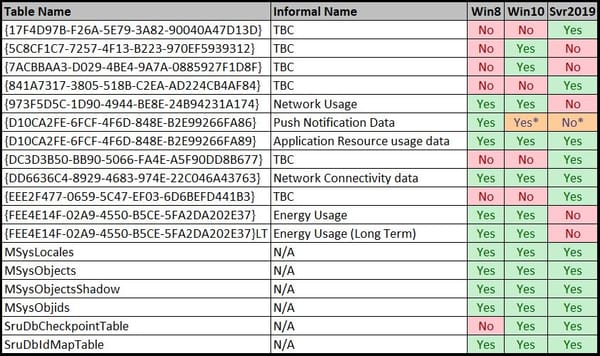
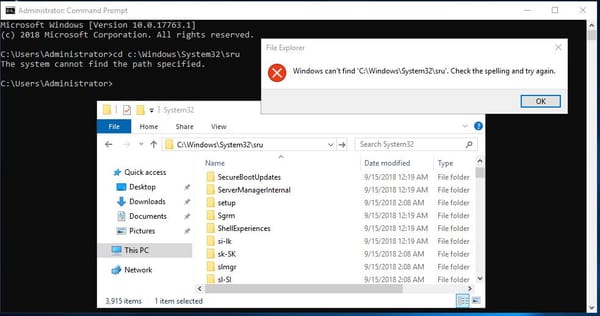
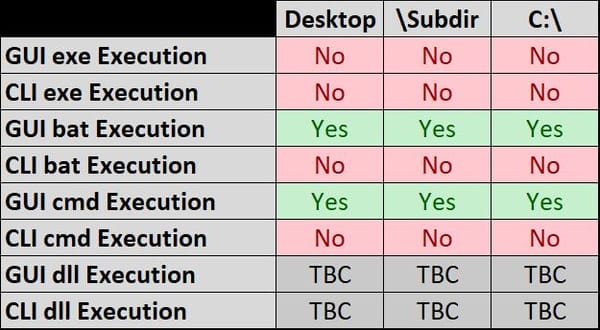
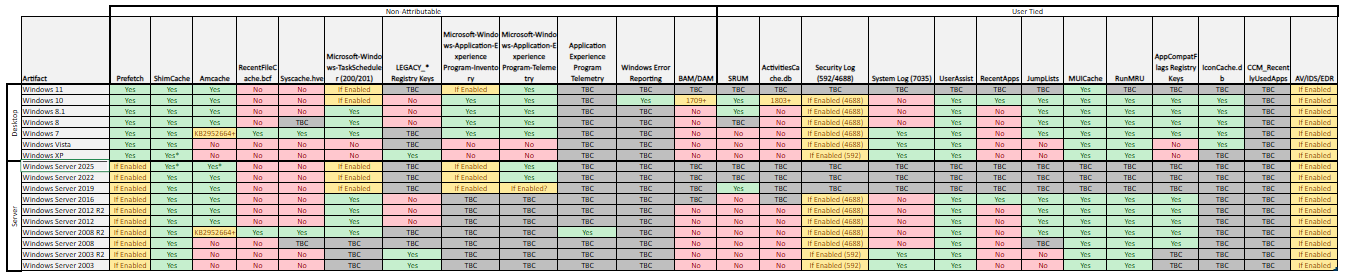
Recently while researching for my recent blog post on ‘Methods to identify historical Time Zone configuration associated with a Windows PC’, I found myself hunting for Regback data within Windows 10 systems with limited success.
Specifically, across multiple system installed with Windows 10 1607, 1703 and 1803 I was finding